PostgreSQL with Timescale is the ultimate storage partner for Grafana

You landed at the right article if you wonder what database to choose for your commercial Grafana-based web application. I will share my thoughts on when it should be PostgreSQL, and you can decide if your use case is any close.
This article is written to supplement the YouTube video we recently published on our channel. I will add source code to all my examples below.
Grafana configuration
Grafana stores its configuration (connected data sources, employed visualizations, variables, etc.) in the configuration storage. You end up with an SQLite database after downloading and installing the default Grafana package.
The default setup is excellent for discovering Grafana, but for the Next level (when you design the actual application) you would need to switch to either PostgreSQL or MySQL. PostgreSQL is an excellent choice for capturing Grafana configuration.
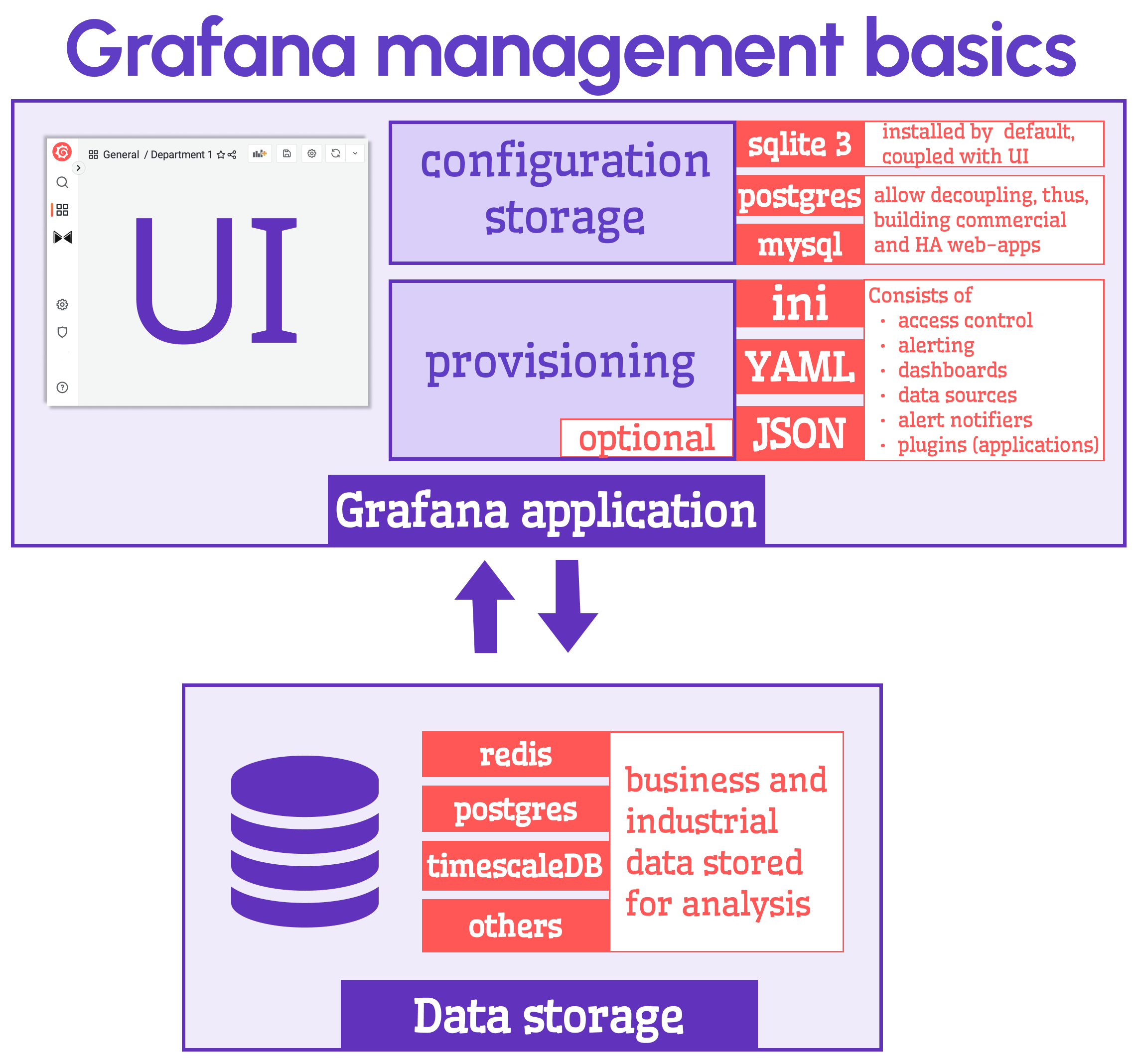
Both databases are open source, and both are supported by Grafana. The benefits are.
- Configuration in a separate container (or host) makes your application design flexible and manageable, with a more straightforward backup/restoration process.
- The separated configuration storage does not get lost when the Grafana UI container is acting up.
- You also can use it for as many UI instances as needed when switching to the High Availability setup.
PostgreSQL
In the video above, I demonstrated how to redirect Grafana UI to a PostgreSQL database. Below I leave the same instructions.
Make sure you have a dedicated PostgreSQL database created. You can surely use the one that is already part of your application ecosystem. Creating a brand new PostgreSQL database is preferable to keep things clean and organized.
Start the PostgreSQL container with TimescaleDB.
docker run -d --name timescaledb -p 5432:5432 \
-e POSTGRES_PASSWORD=password \
timescale/timescaledb:latest-pg14
Start the psql to connect to the database.
docker exec -it timescaledb psql -h localhost -p 5432 -U postgres -w
Create database
Create a new database to store Grafana UI configuration.
create database grafana_configuration_database;
Verify the database is created. It should appear in the output listing.
\l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
--------------------------------+----------+----------+---------+---------+-----------------------
grafana_configuration_database | postgres | UTF8 | C.UTF-8 | C.UTF-8 |
postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 |
template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(4 rows)
Make the new database current.
\c grafana_configuration_database
You are now connected to database "grafana_configuration_database" as user "postgres".
Review the list of existing relations. It should be none.
\d
Did not find any relations.
Start Grafana
Next, run your Grafana UI container and point it to the PostgreSQL database.
docker run --network=host -e GF_DATABASE_TYPE=postgres \
-e GF_DATABASE_HOST=localhost:5432 \
-e GF_DATABASE_NAME=grafana_configuration_database \
-e GF_DATABASE_USER=postgres \
-e GF_DATABASE_PASSWORD=password grafana/grafana:latest
You need to reassign five environment variables. Ensure to prefix each with -e. Do not forget all environment variables' names should be in upper case.
Now, if you switch back to the psql and run the command to list all relations, you should see ~114 objects (in Grafana v9.3.X).
\d
List of relations
Schema | Name | Type | Owner
--------+---------------------------------+----------+----------
public | alert | table | postgres
public | alert_configuration | table | postgres
public | alert_configuration_id_seq | sequence | postgres
public | alert_id_seq | sequence | postgres
public | alert_instance | table | postgres
public | alert_notification | table | postgres
....
That's it. Your Grafana UI will now work with the PostgreSQL database. Go ahead, make some changes in Grafana and find them in the database.
TimescaleDB is a PostgreSQL extension
The second reason to love PostgreSQL is its particular extension for time-series data Timescale. The huge Timescale advantage is its SQL support. You are free to mix two data formats, relational and time-series, in the same instance and query both via familiar and dearly loved SQL.
All time-series-specific functions are designed in a way to fit into SQL clauses. Combining two very needed formats is simply genius and, honestly, satisfying.
Aggregation
In the video above, I briefly explain one possible data aggregation. My original table has 5-minute stock ticks. The data comes from the twelvedata website via API calls.
Timescale does aggregations by creating Materialized views. You need to specify which field from your original table is time and convert it into bucket. The materialized view will be updated on any original table data changes without slowing down anything.
In my example, I chose to aggregate 5-minute ticks into 1-hour ticks.
CREATE MATERIALIZED VIEW one_hour_candle
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 hour', datetime) AS bucket,
stock_symbol,
FIRST(open, datetime) AS "open",
MAX(high) AS high,
MIN(low) AS low,
LAST(close, datetime) AS "close",
LAST(volume, datetime) AS volume
FROM stocks
GROUP BY bucket, stock_symbol;
Hypertable
The table stocks to capture stock data is a hyper table. I created it as a regular and converted it into a hyper table. The first parameter is a table name to convert, and the second is a column name with a timestamp.
create table stocks (
datetime timestamptz,
open real,
high real,
low real,
close real,
volume integer,
stock_symbol text
);
SELECT create_hypertable('stocks', 'datetime');
Relational data
And the third reason we love PostgreSQL is that it is the world's most advanced open source relational database.
This fact, along with time-series ability and using PostgreSQL for configuration storage, makes it an ultimate choice for Grafana. Working with one database for all your needs is more accessible than with many different kinds.
Load stock data from a file into the stocks table.
COPY stocks FROM '/tmp/time_series-TSLA-5min.csv' (DELIMITER(';'), HEADER TRUE, FORMAT CSV);
update tesla_stocks set stock_symbol = 'TSLA';
Create a table to capture descriptive information along with logo images.
create table stock_image (
stock_symbol text,
stock_name text,
scaleX real,
scaleY real,
image_svgxml text
);
Populate the stock_image table.
Note, I replaced the symbol # with %23 in the fill attribute.
fill="#f90" change to fill="%23f90"
insert into stock_image (stock_symbol, stock_name, scaleX, scaleY,image_svgxml) VALUES('AMZN','Amazon',
0.1, 0.1,'<svg xmlns="http://www.w3.org/2000/svg" width="936.713" height="282"><g fill-rule="evenodd"><path fill="%23f90" d="M581.09 220.539c-54.231 40.1-133.112 61.462-201.147 61.462-95.315 0-180.769-35.168-245.846-93.671-4.93-4.6-.657-10.846 5.587-7.231 70.007 40.755 156.448 65.077 245.846 65.077 60.147 0 126.538-12.489 187.671-38.455 9.2-3.615 16.762 6.245 7.888 12.818Z" data-name="Path 19"/><path fill="%23f90" d="M603.769 194.574c-6.9-8.874-46.014-4.273-63.433-1.972-5.259.657-6.245-3.944-1.315-7.231 31.224-22.021 82.168-15.448 88.084-8.217s-1.643 58.5-30.9 82.825c-4.6 3.615-8.874 1.643-6.9-3.287 6.576-16.434 21.366-52.918 14.464-62.118Z" data-name="Path 20"/><path d="M541.321 30.9V9.531a5 5 0 0 1 5.259-5.259h95.315a5.477 5.477 0 0 1 5.588 5.259v18.077c0 2.958-2.629 6.9-7.231 13.476l-49.3 70.336c18.406-.329 37.8 2.3 54.231 11.5 3.615 1.972 4.6 5.259 4.93 8.217v22.678c0 3.287-3.287 6.9-6.9 4.93-29.252-15.448-68.364-17.091-100.573.329-3.287 1.643-6.9-1.643-6.9-4.93v-21.69c0-3.287 0-9.2 3.615-14.461l57.189-81.839h-49.635a5.477 5.477 0 0 1-5.588-5.254ZM193.916 163.349h-28.923a5.935 5.935 0 0 1-5.259-4.93V9.86a5.477 5.477 0 0 1 5.587-5.259h26.951a5.357 5.357 0 0 1 5.259 4.93v19.392h.657c6.9-18.734 20.378-27.608 38.126-27.608 18.077 0 29.58 8.874 37.469 27.608 6.9-18.734 23.007-27.608 40.1-27.608 12.161 0 25.308 4.93 33.525 16.434 9.2 12.489 7.231 30.566 7.231 46.671v94a5.477 5.477 0 0 1-5.587 5.259h-28.598c-2.958-.329-5.259-2.629-5.259-5.259V79.538c0-6.245.657-22.021-.657-27.937-2.3-9.86-8.545-12.818-17.091-12.818a19.354 19.354 0 0 0-17.42 12.161c-2.958 7.559-2.629 20.049-2.629 28.594v78.882a5.477 5.477 0 0 1-5.587 5.259h-28.923c-2.958-.329-5.259-2.629-5.259-5.259V79.538c0-16.434 2.629-41.084-17.748-41.084-20.706 0-20.049 23.664-20.049 41.084v78.882a5.773 5.773 0 0 1-5.916 4.93ZM729.65 1.315c43.056 0 66.392 36.811 66.392 83.811 0 45.357-25.636 81.51-66.392 81.51-42.07 0-65.077-36.811-65.077-82.825-.329-46.343 23.007-82.5 65.077-82.5Zm0 30.566c-21.364 0-22.678 29.252-22.678 47.329s-.329 56.86 22.35 56.86c22.35 0 23.664-31.224 23.664-50.287 0-12.49-.657-27.608-4.273-39.441-3.287-10.518-9.86-14.461-19.063-14.461Zm121.937 131.468h-28.923c-2.958-.329-5.259-2.629-5.259-5.259V9.2a5.681 5.681 0 0 1 5.588-4.93h26.951a5.62 5.62 0 0 1 5.259 4.273v22.678h.657c8.217-20.378 19.392-29.909 39.441-29.909 12.818 0 25.636 4.6 33.853 17.42 7.559 11.832 7.559 31.881 7.559 46.343v93.671a5.408 5.408 0 0 1-5.588 4.6H902.2c-2.629-.329-4.93-2.3-5.259-4.6V77.895c0-16.434 1.972-40.1-18.077-40.1-6.9 0-13.475 4.6-16.762 11.832-3.944 9.2-4.6 18.077-4.6 28.266v80.2a6.019 6.019 0 0 1-5.916 5.259ZM465.4 92.357c0 11.175.329 20.706-5.259 30.9-4.6 8.217-11.832 13.147-20.049 13.147-11.175 0-17.748-8.545-17.748-21.035 0-24.65 22.021-29.252 43.056-29.252Zm29.252 70.664a5.942 5.942 0 0 1-6.9.657c-9.531-7.888-11.5-11.832-16.762-19.392-15.776 16.1-27.28 21.035-47.657 21.035-24.322 0-43.385-15.119-43.385-45.028 0-23.664 12.818-39.44 30.9-47.329 15.776-6.9 37.8-8.217 54.559-10.189V59.16c0-6.9.657-15.119-3.615-21.035-3.615-5.259-10.189-7.559-16.1-7.559-11.175 0-21.035 5.587-23.336 17.42-.657 2.629-2.3 5.259-4.93 5.259l-27.937-2.958c-2.3-.657-4.93-2.3-4.273-5.916C391.789 10.189 422.356 0 449.964 0c14.133 0 32.538 3.615 43.713 14.461 14.133 13.147 12.818 30.9 12.818 49.958v45.028c0 13.476 5.587 19.392 10.846 26.951 1.972 2.629 2.3 5.916 0 7.559-6.245 4.93-16.762 14.133-22.678 19.063ZM85.783 92.357c0 11.175.329 20.706-5.259 30.9-4.6 8.217-11.832 13.147-20.049 13.147-11.175 0-17.748-8.545-17.748-21.035 0-24.65 22.021-29.252 43.056-29.252Zm28.923 70.664a5.942 5.942 0 0 1-6.9.657c-9.531-7.888-11.5-11.832-16.762-19.392-15.776 16.1-27.28 21.035-47.657 21.035-24.322 0-43.385-15.119-43.385-45.028 0-23.664 12.818-39.44 30.9-47.329 15.776-6.9 37.8-8.217 54.559-10.189V59.16c0-6.9.657-15.119-3.615-21.035-3.615-5.259-10.189-7.559-16.1-7.559-11.175 0-21.035 5.587-23.336 17.42-.657 2.629-2.3 5.259-4.93 5.259L9.543 50.287c-2.3-.657-4.93-2.3-4.273-5.916C11.843 10.189 42.41 0 70.018 0c14.133 0 32.538 3.615 43.713 14.461 14.133 13.147 12.818 30.9 12.818 49.958v45.028c0 13.476 5.587 19.392 10.846 26.951 1.972 2.629 2.3 5.916 0 7.559-6.245 4.93-16.762 14.133-22.678 19.063Z" data-name="Path 21"/></g></svg>');
insert into stock_image (stock_symbol, stock_name, scaleX, scaleY, image_svgxml) VALUES('TSLA', 'Tesla', 0.1, 0.1, '<svg xmlns="http://www.w3.org/2000/svg" width="1242" height="161" viewBox="0 0 278.7 36.3"><path fill="%235e5e5e" d="M238.1 14.4v21.9h7V21.7h25.6v14.6h7V14.4h-39.6M244.3 7.3h27c3.8-.7 6.5-4.1 7.3-7.3H237c.8 3.2 3.6 6.5 7.3 7.3M216.8 36.3c3.5-1.5 5.4-4.1 6.2-7.1h-31.5V.1h-7.1v36.2h32.4M131.9 7.2h25c3.8-1.1 6.9-4 7.7-7.1H125v21.4h32.4V29H132c-4 1.1-7.4 3.8-9.1 7.3h41.5V14.4H132l-.1-7.2M70.3 7.3h27c3.8-.7 6.6-4.1 7.3-7.3H62.9c.8 3.2 3.6 6.5 7.4 7.3M70.3 21.6h27c3.8-.7 6.6-4.1 7.3-7.3H62.9c.8 3.2 3.6 6.5 7.4 7.3M70.3 36.3h27c3.8-.7 6.6-4.1 7.3-7.3H62.9c.8 3.2 3.6 6.6 7.4 7.3M0 .1c.8 3.2 3.6 6.4 7.3 7.2h11.4l.6.2v28.7h7.1V7.5l.6-.2h11.4c3.8-1 6.5-4 7.3-7.2V0L0 .1"/></svg>');
insert into stock_image (stock_symbol, stock_name, scaleX, scaleY, image_svgxml) VALUES('UNH', 'United Healthcare', 1, 1, '<svg xmlns="http://www.w3.org/2000/svg" width="1200" height="60"><g transform="matrix(1.25 0 0 -1.25 -567.56049 1468.0435)"><path d="M458.397 1157.934v-12.41c0-4.712.843-5.86 1.888-6.05.128-.023.257-.033.39-.033.67 0 2.235.337 3.107 3.48.39 1.397.487 4.23.487 6.115v12.044l-5.87-3.146" fill="%23263d96"/><g fill="%23fff"><path d="M466.75 1148.685v-.122l-.001-.038v-.32c-.001-.012-.001-.023-.001-.036v-.032l-.001-.02v-.107l-.001-.052v-.033l-.001-.02v-.107l-.002-.05v-.054l-.001-.05v-.043-.072-.042-.023l-.002-.05v-.066l-.002-.05-.001-.043-.001-.023-.001-.05-.001-.042v-.022-.05l-.001-.04-.001-.025-.001-.048v-.066l-.002-.048-.002-.04-.001-.026v-.048l-.001-.04-.001-.026-.002-.048-.001-.04-.001-.027-.002-.048-.001-.04-.002-.027-.002-.048-.001-.04c0-.012-.002-.018-.002-.027l-.002-.05c0-.023-.001-.03-.002-.04l-.001-.028-.002-.047-.002-.04-.001-.027-.003-.05-.002-.04-.001-.028-.002-.048c0-.023-.002-.03-.002-.04s-.001-.02-.002-.028l-.002-.048-.001-.038-.002-.03-.003-.048-.002-.036-.002-.03-.003-.048-.002-.038c0-.012-.002-.02-.002-.03l-.002-.05-.003-.036-.002-.03a.36.36 0 0 0-.002-.047l-.003-.038-.002-.03-.002-.048-.002-.036-.002-.03-.004-.048v-.035l-.002-.032c-.002-.012-.003-.023-.003-.036l-.005-.035c-.002-.012-.002-.022-.004-.032l-.004-.036-.003-.035-.002-.032c-.001-.012-.003-.022-.003-.035l-.003-.036-.002-.032a.41.41 0 0 1-.005-.038l-.005-.035c0-.012-.001-.02-.002-.034s-.002-.022-.004-.034l-.005-.038-.004-.032-.004-.038-.003-.036a.34.34 0 0 1-.005-.034c-.002-.012-.002-.023-.004-.035l-.005-.036c-.002-.012-.004-.023-.005-.033l-.006-.038-.005-.036-.006-.035c-.002-.012-.004-.023-.005-.035l-.005-.036-.006-.035-.004-.036-.005-.035c-.002-.012-.002-.022-.005-.035l-.006-.036-.005-.036-.006-.035-.007-.035c-.003-.03-.005-.032-.006-.036l-.006-.036c-.002-.012-.002-.023-.005-.036l-.005-.036c-.002-.012-.002-.022-.006-.035l-.006-.036c-.003-.03-.005-.03-.006-.036l-.005-.036-.008-.034c-.001-.012-.002-.012-.002-.02l-.01-.052-.007-.035-.005-.036-.007-.036c-.002-.012-.004-.022-.007-.033s-.002-.013-.004-.02l-.01-.052-.008-.036-.006-.035-.007-.036-.007-.033c-.002-.012-.004-.014-.006-.02l-.01-.05c-.002-.012-.006-.022-.007-.034l-.004-.02-.01-.052c-.002-.012-.006-.02-.008-.032s-.002-.014-.004-.02v-.05c-.005-.012-.007-.022-.01-.033s-.004-.013-.006-.02l-.012-.05c-.003-.012-.007-.022-.008-.033s-.004-.015-.006-.022l-.012-.05c-.003-.012-.007-.022-.008-.032s-.004-.014-.006-.022l-.013-.05c-.005-.023-.01-.033-.012-.043s-.004-.013-.006-.02l-.013-.05a.1.1 0 0 1-.011-.032c-.002-.012-.005-.015-.007-.023l-.013-.048-.01-.032c-.007-.02-.008-.03-.01-.032-.002-.012-.006-.023-.01-.036a.2.2 0 0 1-.011-.032c-.002-.012-.004-.015-.007-.023-.006-.025-.01-.035-.014-.048-.005-.023-.008-.03-.01-.04s-.006-.015-.007-.025c-.005-.018-.012-.035-.018-.053l-.018-.055-.02-.054-.02-.055-.02-.054-.022-.054-.02-.054-.02-.055-.023-.054-.022-.055-.023-.054-.025-.054-.024-.054-.025-.055-.027-.053c-.007-.02-.017-.038-.026-.055l-.027-.054-.027-.055-.027-.054-.028-.055-.03-.054-.028-.054-.03-.054-.03-.055-.03-.054-.03-.054-.032-.054-.032-.055-.068-.108-.035-.054-.036-.054-.037-.055-.037-.054-.076-.108-.04-.055-.04-.055-.083-.108-.043-.054-.046-.055-.044-.054c-.655-.777-1.53-1.428-2.626-1.572l1.638-.197c.956.234 1.802.878 2.465 1.77l.04.054.08.11.038.054.035.054.072.1.035.054c.012.016.023.036.034.054l.03.054.032.055.032.054.032.054.03.054.03.054.027.055.057.108.03.054.027.055.026.054.025.054.026.054.026.055.025.054c.01.018.016.036.024.055s.015.036.022.054l.024.055.023.053.022.055.023.054.02.06.02.054.02.055c.007.016.013.038.02.054l.02.055.038.108c.007.018.012.036.017.054l.018.055.016.054.016.055c.007.016.012.035.017.053.002.012.005.016.007.025a.27.27 0 0 0 .011.029c.004.025.01.035.013.048l.01.036.008.032.01.048c.006.025.007.03.01.035l.007.032.012.047c.005.025.007.03.01.036l.007.032a.15.15 0 0 1 .011.038c.005.025.007.028.01.035l.007.032c.005.025.01.035.012.047.005.026.007.03.01.036l.006.032c.004.013.007.023.01.036l.008.036.007.032.008.036c.004.026.006.03.008.036l.007.033c.005.013.008.022.01.035l.01.036.007.033.01.036.007.036.014.068.006.038.007.033.007.036.006.035.007.036.007.035.006.04.007.033.007.036.006.035c.002.012.004.023.005.035s.004.023.007.035l.005.036.006.034h0l.012.073.007.036.005.035.006.036.007.036c.001.012.004.023.006.036l.005.036.007.035.004.035.005.035c.002.012.002.023.005.036s.002.023.004.035l.005.035c.002.013.002.023.004.038l.005.036.005.035c.002.012.002.022.004.035l.004.035.004.02.007.053c.001.012.002.02.005.033s.002.013.002.02l.004.05c.002.013.002.022.004.034s.002.014.002.02l.004.053.004.032c0 .012.001.013.002.02l.004.05.004.034.002.02c.001.027.003.04.004.052l.004.032c.001.012.002.014.002.022l.007.05c0 .012.001.022.002.032s.002.014.002.022l.006.05c0 .012.001.02.002.032l.002.022.004.05.004.043.001.022.003.05.003.042c.001.012.002.015.002.023l.006.05.002.042.002.025a.36.36 0 0 0 .002.047l.003.042.002.025.003.048.002.04.002.026.003.048.002.04.002.025.003.048v.04l.002.026.003.048.003.04c0 .012.001.018.002.027l.002.048.001.04.002.027.002.05.003.04v.027l.003.047.002.04v.027l.003.05c0 .023.001.03.002.04l.001.028.002.048.002.04v.027l.002.048.002.04.001.028.002.048.002.038.001.028.002.048v.038l.002.03.002.05v.036c.002.012.002.02.002.03l.002.047.002.036.001.03v.05l.001.034v.03l.002.048v.036l.002.032.001.048.001.036.001.03v.048l.002.036v.03l.002.048v.035l.001.032v.05l.001.035a.15.15 0 0 0 .002.033v.072l.001.033v.036l.001.035c.001.012.001.022.001.033l.002.073v.033l.002.074v.032l.001.036v.036l.001.034v.107l.001.038v.035l.001.035v.073l.001.034v.038.034.36l.001.038v13.044l-1.335.298v-13.723"/><path d="M469.27 1148.787v-.264c-.001-.012-.001-.022-.001-.035v-.108-.033-.02l-.001-.053v-.07-.036l-.001-.032v-.074c-.001-.012-.001-.022-.001-.033l-.001-.02-.001-.052-.001-.033v-.02l-.001-.052-.001-.033v-.022-.05c-.001-.012-.001-.02-.001-.032l-.001-.022-.001-.05v-.043l-.001-.02-.001-.05-.001-.042-.001-.023-.001-.05-.002-.042v-.023l-.002-.05-.001-.043v-.023l-.001-.05-.002-.042-.001-.022-.002-.05v-.04l-.002-.025-.001-.047-.002-.04-.001-.025-.002-.048v-.04l-.002-.026-.002-.048-.001-.04-.002-.026v-.048l-.002-.04-.002-.027-.004-.087-.002-.027-.002-.048-.002-.04-.002-.027-.003-.05-.002-.04-.002-.028-.003-.047c0-.023-.001-.03-.002-.04s-.001-.018-.002-.027l-.002-.05-.003-.04v-.028l-.004-.048-.002-.04-.002-.028-.003-.048-.002-.038-.001-.03-.006-.048-.002-.036-.002-.03-.002-.048-.003-.038c0-.012-.001-.02-.002-.03l-.002-.05-.003-.036c0-.012-.002-.02-.002-.03l-.004-.047-.003-.036-.002-.03-.004-.05-.002-.035-.002-.03-.004-.048-.003-.035-.002-.032c-.002-.012-.003-.023-.003-.036l-.003-.035-.002-.032c-.002-.013-.002-.025-.004-.036l-.005-.035-.004-.032-.004-.035-.005-.036c-.002-.012-.002-.022-.004-.032s-.004-.025-.004-.038l-.005-.035-.004-.034c-.002-.012-.002-.022-.004-.034l-.005-.038c-.002-.012-.002-.02-.004-.032l-.004-.038-.005-.036-.004-.034-.004-.035-.005-.036c-.002-.012-.002-.023-.005-.033s-.002-.025-.005-.038l-.005-.036c-.002-.012-.002-.022-.004-.035l-.006-.035-.005-.036-.006-.035-.006-.038-.004-.036c-.002-.012-.002-.022-.006-.035l-.006-.036-.003-.036-.006-.035v-.001c-.001-.013-.002-.023-.006-.035l-.006-.036c-.001-.013-.004-.025-.005-.036l-.006-.036-.005-.036-.007-.035c-.002-.013-.002-.025-.005-.036-.003-.03-.005-.03-.006-.036l-.006-.036v-.001l-.006-.034c-.002-.012-.002-.013-.002-.02l-.01-.052-.007-.035-.005-.035-.007-.036c-.001-.012-.004-.022-.006-.033s-.002-.013-.004-.02l-.01-.052-.007-.038-.006-.035-.007-.036c-.003-.012-.004-.022-.007-.033s-.002-.014-.005-.02l-.01-.05-.008-.034c-.001-.012-.002-.013-.002-.02l-.01-.052c-.002-.012-.006-.02-.007-.032s-.002-.014-.005-.02l-.01-.05-.007-.033c-.001-.012-.002-.014-.005-.02l-.01-.05-.008-.033c-.002-.012-.004-.015-.006-.022l-.01-.05c-.003-.012-.007-.02-.008-.032s-.004-.015-.006-.022l-.01-.05-.008-.043-.005-.02-.013-.05-.008-.032-.005-.023-.012-.048c-.005-.012-.008-.022-.01-.032s-.005-.016-.007-.022c-.005-.026-.008-.036-.012-.05a.19.19 0 0 1-.009-.032c-.002-.012-.005-.015-.007-.023l-.012-.048-.01-.04c-.002-.012-.005-.015-.007-.025l-.016-.053c-.004-.02-.01-.036-.015-.055l-.015-.054-.016-.055-.015-.054-.034-.108-.017-.055-.017-.054-.017-.055c-.007-.016-.012-.036-.018-.054l-.02-.054-.02-.054c-.005-.02-.012-.036-.018-.055l-.02-.053c-.006-.02-.013-.038-.02-.055l-.02-.054-.02-.055-.02-.054-.02-.055-.022-.054-.023-.054-.022-.054-.022-.055-.047-.108-.023-.054c-.004-.012-.007-.016-.012-.022-.004-.012-.01-.022-.013-.033-.01-.016-.018-.035-.027-.054l-.08-.162-.03-.055-.057-.108-.03-.054-.03-.055-.03-.055-.03-.054-.032-.054-.033-.054-.03-.055-.036-.054c-.773-1.24-2.174-2.76-4.112-2.777l1.878-.226c1.36.237 2.784 1.318 3.7 3.003.01.018.02.038.028.054l.027.055c.01.018.02.036.028.054l.028.054.027.054.026.047.027.067.05.108.025.054.025.055.023.054.025.054.022.054.023.054.022.055.044.108.02.054.022.055.02.054.02.054.02.054.02.055.02.054.018.055.018.054.018.055.018.053.017.055.034.108c.007.018.012.036.017.054l.015.055.016.054.016.055.045.162.015.055.014.054c.006.018.01.036.014.055s.01.035.014.053c.002.012.004.018.007.025l.007.03c.004.023.007.035.01.048l.008.035c.002.012.006.02.007.032s.01.025.01.036c.005.025.007.028.01.035s.005.022.007.032l.01.035.008.036c.004.012.006.02.007.032s.007.025.01.036l.007.035.007.032.01.047c.004.026.006.03.008.036l.007.032.01.036.007.036.007.032c.002.013.006.023.007.036l.007.035.006.033c.005.013.005.022.01.035l.007.036.007.032.007.036.006.036.007.034c.002.012.003.022.007.034l.006.038.007.033.007.036.006.035.006.036.007.036.006.038.007.033.006.036.006.036.006.035c.003.012.003.023.006.035l.006.036.006.034v.001l.007.036.005.036.006.036.006.035.005.036.012.073.005.036c.001.012.002.022.005.035l.006.035.005.036.006.036c.001.013.002.023.005.035l.005.035c.002.013.004.023.005.038l.006.036.005.035c.001.012.002.022.005.035l.004.035c.001.012.002.013.002.02l.006.053.004.033c.001.012.002.013.002.02l.007.05c.002.012.002.022.002.034l.004.02.01.085c.001.012.002.013.002.02l.006.05.004.034c0 .012.001.013.002.02l.005.052.004.032.002.022.007.05c.002.012.002.022.002.032s.002.014.002.022l.004.05c.002.012.002.02.003.032s.002.014.002.022l.004.05.003.043.002.022.004.05.003.042c.001.012.002.015.002.023l.004.05a.26.26 0 0 0 .002.042l.002.025.003.047.003.042c0 .012.002.015.002.025l.005.048.003.04c.001.012.002.016.002.026l.003.048.002.04.002.025.003.048.004.04c0 .012.001.016.002.026l.002.048.002.04.002.027.003.048.002.04c0 .012.001.018.002.027l.002.05.003.04c0 .012.001.016.002.027l.002.047.003.04v.027l.002.048.003.04.001.028.002.048v.04c.002.012.002.018.002.027l.002.048.005.04v.028l.001.048.002.038.002.028.002.048.002.038.002.03.002.05.002.036.002.03v.047l.001.036c0 .012.001.02.002.03l.002.05.001.034c.001.012.001.02.001.03v.048l.002.035.001.032.002.048.001.036.001.03.002.048v.036l.001.03.002.048v.036c.001.012.001.022.001.032l.002.038.001.035c.001.012.001.022.001.033l.002.035.001.036.001.033.002.073.001.032.007.248v.036l.001.034.001.036v.038l.001.033v.073.035l.001.035v.038l.001.034v.038.034.073.036.035c.001.012.001.025.001.038v.07l.001.036v.143l.001.038v14.317l-1.36.304v-14.973"/></g><g fill="%23263d96"><path d="M469.27 1163.76l1.36-.304-.01-15.25c-.001-.012-.001-.023-.001-.036l-.001-.033c0-.013 0-.015-.001-.02l-.001-.053-.001-.033c0-.01-.001-.013-.001-.02l-.001-.052-.001-.032-.001-.022-.001-.052-.001-.032-.001-.022-.002-.05-.001-.043-.001-.022a.43.43 0 0 0-.002-.05l-.001-.043v-.022a.41.41 0 0 0-.002-.05l-.001-.042-.001-.023a.42.42 0 0 0-.002-.049l-.001-.042-.001-.023-.002-.05-.001-.032-.001-.023-.002-.05-.003-.064-.002-.05v-.065l-.003-.048c0-.023-.001-.03-.002-.04s0-.015-.001-.025a.65.65 0 0 0-.003-.049.24.24 0 0 0-.002-.041l-.001-.026a.65.65 0 0 0-.003-.048l-.002-.04-.001-.026v-.088l-.002-.027-.003-.048-.005-.04v-.027l-.002-.048-.002-.04-.002-.027-.003-.05v-.04l-.002-.028-.003-.047-.002-.04-.002-.028-.003-.05-.002-.04v-.028-.048l-.003-.04-.002-.028-.002-.048-.002-.038-.002-.03-.003-.048-.003-.036c-.001-.008-.001-.02-.001-.03l-.003-.048-.003-.038-.002-.03-.003-.05-.005-.036-.002-.03-.003-.047-.003-.038-.002-.03-.007-.084-.002-.03-.008-.083-.002-.032a.51.51 0 0 1-.004-.036l-.003-.035v-.032a.76.76 0 0 1-.004-.036l-.003-.035-.002-.032a.32.32 0 0 1-.005-.035l-.003-.036-.004-.032a.25.25 0 0 1-.003-.038l-.005-.035-.008-.068-.005-.038-.004-.032c-.002-.01-.002-.025-.004-.038l-.006-.036a.28.28 0 0 0-.002-.034c-.002-.012-.002-.023-.005-.035l-.005-.036-.004-.033a.65.65 0 0 1-.004-.038l-.005-.036c-.002-.012-.002-.022-.004-.035l-.005-.035-.005-.036-.005-.035-.006-.04-.005-.036a.32.32 0 0 1-.005-.035l-.006-.038-.005-.035-.006-.035s-.006-.023-.007-.035l-.005-.036-.012-.072-.005-.036-.006-.035-.006-.036-.005-.036-.007-.036-.006-.034-.004-.02-.007-.053-.007-.035c-.003-.03-.005-.03-.006-.035a.34.34 0 0 1-.005-.036l-.008-.033h-.004l-.01-.052-.006-.038-.006-.035-.007-.036-.007-.033c-.001-.012-.002-.014-.004-.02l-.008-.05-.008-.034-.004-.02-.01-.052c-.002-.012-.006-.02-.007-.032s-.002-.014-.005-.02l-.01-.05-.008-.033c-.002-.01-.002-.014-.005-.022v-.05a.69.69 0 0 0-.007-.032c-.002-.012-.002-.015-.005-.022-.005-.027-.008-.038-.012-.05a.69.69 0 0 0-.007-.032l-.005-.022-.01-.05-.01-.043s-.002-.013-.005-.022l-.01-.05s-.004-.022-.008-.032-.004-.015-.006-.023l-.01-.048s-.007-.022-.008-.032-.004-.016-.007-.022c-.003-.025-.007-.036-.01-.05a.19.19 0 0 1-.009-.032c-.001-.012-.002-.015-.006-.023l-.013-.05c-.002-.023-.005-.03-.007-.04s-.005-.015-.007-.025l-.014-.053-.014-.055-.014-.054-.015-.055-.045-.162-.016-.055-.016-.054-.015-.055-.067-.217-.018-.053-.018-.055-.018-.054-.018-.055-.02-.054-.02-.055-.02-.054a.82.82 0 0 1-.019-.054l-.02-.054-.022-.055-.02-.054-.044-.108-.022-.055-.023-.054-.022-.054-.025-.054-.023-.054-.025-.055-.025-.054a.34.34 0 0 0-.026-.054c-.01-.016-.017-.038-.026-.054s-.016-.038-.025-.055c-.01-.027-.02-.043-.028-.06l-.027-.054-.028-.054a.63.63 0 0 0-.028-.054l-.027-.055-.028-.054c-.917-1.684-2.34-2.766-3.7-3.003l-1.878.226c1.937.018 3.34 1.538 4.112 2.777l.036.054.03.055.033.054.032.054.03.054.06.1.03.054a.9.9 0 0 1 .028.054l.028.054.03.055a.96.96 0 0 1 .027.054l.053.108a.55.55 0 0 0 .027.054c.004.012.01.022.013.032s.007.016.012.022l.023.054a.83.83 0 0 0 .024.054l.024.054.022.055.022.054.023.054.022.054c.008.016.013.038.02.055l.02.054.02.055v.054l.02.055c.006.02.013.035.02.053s.013.036.018.055a.35.35 0 0 0 .02.054c.008.018.012.036.02.054s.012.038.018.054l.017.055a.56.56 0 0 1 .017.054l.017.055a1.91 1.91 0 0 1 .017.054l.017.054.015.054.016.055.015.054c.006.018.012.036.015.055s.012.035.016.053c.002.012.005.018.007.025l.008.03c.003.025.007.035.01.048.005.025.006.03.01.036s.005.02.007.032.01.023.012.036c.005.025.007.028.01.035s.005.022.007.032a.2.2 0 0 1 .011.035l.008.036s.006.02.007.032.008.025.01.038l.008.035s.006.022.007.032c.003.023.007.035.01.047.005.026.005.03.008.036s.005.02.007.032.006.023.01.036l.008.036a.69.69 0 0 0 .007.032c.003.013.007.025.008.036l.007.036.007.033a.38.38 0 0 1 .008.035l.007.036a.69.69 0 0 0 .007.032l.007.036.006.036a.26.26 0 0 0 .007.034.14.14 0 0 0 .008.034l.007.038.006.033a.39.39 0 0 1 .008.036l.006.035.014.072.006.038.006.033.007.036.005.035.007.035.006.035.006.038.006.034.012.074.005.036.007.035.005.036.006.036.005.036.006.036a.32.32 0 0 0 .006.035l.006.036.003.035.012.072.004.035.006.038.006.035.005.036.006.035.004.035c.002.012.002.012.002.02l.007.053s.002.02.005.033.002.013.002.02l.006.05.004.034.002.02.006.053a.64.64 0 0 1 .004.033c.001.012.002.013.002.02l.006.05.004.034c.002.012.002.013.002.02l.005.052a.6.6 0 0 1 .004.032c0 .012.002.015.002.022a.59.59 0 0 1 .007.049l.004.032v.022l.006.05.002.032s.002.014.002.022l.003.05.003.043.002.022.004.05.003.042.002.023.004.05.003.042.002.025.004.048.003.042a.24.24 0 0 0 .002.025l.003.05v.04.026l.003.048.002.04v.025l.003.048v.04l.002.026.002.048.005.067.004.048v.04s.002.016.002.027l.003.048v.04.027l.002.047.005.067.002.05.003.04.001.028.003.048v.04l.001.027.003.048c0 .023.001.03.002.04s0 .018.001.028l.003.048.002.038v.028l.002.048.002.038v.03l.002.05.001.036.002.03v.047.038l.001.03v.05l.001.035.001.03.002.048v.067l.002.048.001.035v.03.048l.002.036v.03l.002.048v.068l.001.05v.067l.001.035v.036a.38.38 0 0 1 .001.032l.001.038v.036a.38.38 0 0 1 .001.032l.003.106v.074c.001.012.001.022.001.032v.106a.46.46 0 0 0 .001.036v.038l.001.033v.107l.001.035v15.237l-2.522-1.352 1.335-.298v-13.043c-.001-.012-.001-.023-.001-.036v-.434c-.001-.012-.001-.022-.001-.034v-.073l-.001-.035v-.035l-.001-.036v-.107c-.001-.012-.001-.022-.001-.034v-.036c-.001-.012-.001-.023-.001-.036v-.158l-.001-.052-.001-.032v-.022-.052-.104l-.003-.065v-.113l-.002-.05v-.115l-.001-.042-.001-.023v-.048l-.002-.032v-.07-.042-.022-.05l-.001-.04-.001-.025v-.048l-.002-.04v-.025l-.002-.05c0-.023-.001-.032-.002-.04v-.026-.048-.04l-.002-.026v-.048l-.001-.04-.001-.027-.002-.048-.002-.04c0-.012-.001-.016-.002-.027v-.088l-.002-.027-.002-.05-.002-.04-.001-.028-.003-.047-.002-.04-.002-.027-.003-.048-.002-.04v-.028l-.003-.048-.002-.04-.002-.028-.003-.048c-.003-.023-.003-.03-.003-.038l-.001-.03-.003-.048-.003-.036v-.078l-.003-.038-.002-.03-.002-.05-.003-.036v-.03l-.005-.047-.002-.038v-.03l-.004-.05-.005-.036a.2.2 0 0 0-.002-.031l-.003-.048-.002-.035-.004-.032c-.002-.012-.002-.023-.004-.036l-.003-.035v-.032c0-.01-.002-.025-.004-.036l-.005-.035-.002-.032s-.002-.022-.005-.035l-.005-.036-.004-.032c-.002-.01-.004-.025-.004-.038l-.003-.035-.004-.034a.53.53 0 0 1-.004-.034l-.003-.038-.004-.033c-.002-.01-.003-.025-.004-.038l-.003-.036-.004-.034c-.002-.012-.002-.023-.004-.035l-.003-.036-.005-.033s-.002-.023-.005-.036l-.006-.036-.008-.07-.005-.036-.005-.035-.004-.04-.005-.035-.004-.035s-.002-.025-.005-.038l-.005-.035-.004-.035-.007-.036-.005-.036a.39.39 0 0 1-.006-.036l-.007-.036-.006-.036c-.002-.012-.002-.022-.005-.035l-.007-.036-.012-.073-.006-.034-.002-.02-.008-.053-.012-.07-.007-.036-.007-.033c-.003-.01-.002-.013-.004-.02l-.01-.052-.007-.036-.006-.035-.007-.036-.007-.033c-.003-.01-.002-.014-.004-.02l-.01-.05-.007-.034-.004-.02-.012-.052a.55.55 0 0 1-.008-.032c-.002-.012-.004-.014-.006-.02v-.05-.033c-.004-.01-.004-.013-.005-.022l-.01-.05a.56.56 0 0 1-.008-.032c-.002-.012-.004-.015-.006-.022l-.012-.05-.007-.032-.007-.022-.012-.05c-.003-.023-.007-.033-.01-.043s-.005-.013-.007-.022a.57.57 0 0 0-.011-.05c-.005-.012-.008-.022-.01-.032s-.005-.015-.007-.023c-.005-.026-.01-.036-.012-.048s-.007-.022-.01-.032l-.007-.022-.012-.05-.01-.032c-.003-.012-.005-.015-.007-.023-.006-.025-.01-.036-.015-.05-.003-.023-.008-.03-.012-.04s-.005-.015-.007-.025l-.017-.053-.016-.055a.94.94 0 0 1-.016-.054c-.007-.018-.012-.036-.018-.055l-.017-.054a.94.94 0 0 0-.019-.054l-.02-.054a1.19 1.19 0 0 1-.019-.055l-.02-.054-.02-.055-.02-.054-.017-.05a.64.64 0 0 0-.025-.066l-.022-.055-.023-.053-.024-.055c-.01-.02-.013-.038-.022-.054a.44.44 0 0 0-.024-.055L467 1141l-.026-.055-.026-.054-.025-.054-.026-.054-.027-.055-.03-.054-.057-.108-.028-.055-.03-.054a.8.8 0 0 1-.03-.054l-.064-.108-.032-.055-.03-.054a.71.71 0 0 0-.034-.054l-.035-.054a.65.65 0 0 0-.036-.055l-.036-.055-.035-.054-.038-.054a1.19 1.19 0 0 0-.039-.054l-.04-.055-.04-.054c-.664-.9-1.5-1.535-2.465-1.77l-1.638.197c1.095.144 1.97.794 2.626 1.572l.044.054.046.055a2.14 2.14 0 0 0 .043.054l.084.108.08.1.076.108.037.054.037.055c.01.02.024.035.036.054l.035.054.068.108.032.055c.01.02.022.036.032.054l.03.054a.64.64 0 0 1 .031.054l.03.055.03.054.028.054.03.054.028.055.027.054s.02.036.027.055l.027.054.026.055a1.01 1.01 0 0 0 .027.053c.007.02.016.036.025.055a.83.83 0 0 0 .024.054c.007.02.016.036.025.054a.79.79 0 0 0 .023.054l.022.055.023.054.02.055.02.054.022.054.02.054a1.19 1.19 0 0 1 .019.055.82.82 0 0 1 .019.054l.018.055.018.053c.002.012.005.016.007.025l.008.03c.005.025.01.035.013.048l.01.035.008.032c.002.012.01.025.012.036.004.025.007.025.008.032s.007.022.01.033.008.023.01.035l.012.036.008.032c.003.012.01.025.01.038l.01.035.01.032.012.047.01.036.007.032c.002.012.007.023.01.036l.01.036a.69.69 0 0 0 .007.032l.02.072.007.033c.005.013.008.022.01.035l.008.036.008.032.014.073.007.034c.002.012.006.022.007.034l.015.07c.003.01.006.023.007.036l.006.035.008.036.007.036.006.038.007.033.007.036.005.036.014.07.006.036.007.034.006.038.012.073s.002.023.006.035l.005.036c.002.012.002.023.005.036s.004.023.006.036l.006.036.006.035.007.036c.002.03.003.03.005.036l.006.036s.002.026.005.036l.005.035.004.038.006.036.005.035c.001.012.002.022.005.035s.004.023.006.035.002.012.002.02a.61.61 0 0 1 .007.053l.006.033a.18.18 0 0 0 .002.02l.006.05c.001.013.002.022.005.034s.001.014.002.02l.004.053a.84.84 0 0 1 .004.032c.001.012.002.013.002.02l.006.05a.2.2 0 0 1 .002.034c0 .012.002.013.002.02l.007.052v.032l.002.022.003.05.003.033c0 .01.002.014.002.022l.004.05.002.032.002.022.005.05a.61.61 0 0 0 .003.032l.002.022.004.05v.042l.001.023.003.05.002.042v.025l.003.048.002.042.002.025.003.05c0 .023.002.032.002.04s.001.018.002.026l.002.048.003.04v.025l.003.048.003.04v.026l.003.048v.04.027l.002.048.001.04.001.027.003.048v.067l.002.047a.4.4 0 0 1 .002.04l.002.027a1.07 1.07 0 0 1 .001.049l.003.04v.028l.002.048.002.04.001.027a1 1 0 0 1 .001.048l.002.04.001.028v.048l.002.038v.028.048l.001.038v.03l.001.05.001.036v.03l.001.047v.068l.001.048.001.035.001.03a1 1 0 0 1 .001.048v.035a.36.36 0 0 1 .001.032.34.34 0 0 0 .002.036v.066l.002.048v.067l.001.048v.068l.001.05v.066a1.02 1.02 0 0 1 .001.047v.106a.27.27 0 0 0 .001.036v.068l.001.036v.07.038.032.036.32l.001.038v13.845l-2.48-1.328 1.308-.293-.002-11.713c-.001-.012-.001-.023-.001-.036v-.108c-.001-.012-.001-.023-.001-.036v-.372l-.001-.035v-.07c-.001-.012-.001-.025-.001-.036v-.106l-.001-.034v-.036c-.001-.012-.001-.023-.001-.036l-.001-.032v-.02-.053-.033-.072l-.001-.032v-.074c-.001-.012-.001-.02-.001-.032v-.137l-.001-.05-.001-.043-.001-.022-.001-.05v-.042l-.001-.023-.001-.05-.001-.042-.001-.023v-.153l-.001-.042-.001-.022-.002-.05-.001-.04-.001-.025-.002-.048v-.115-.04-.026l-.002-.048-.002-.04-.001-.026a.66.66 0 0 0-.003-.048l-.001-.04s0-.018-.002-.027l-.002-.048-.001-.04-.001-.027v-.048l-.002-.04-.002-.027-.002-.05-.001-.04-.002-.028-.002-.047-.003-.04v-.027l-.002-.05-.003-.04-.001-.028-.003-.048-.003-.04-.001-.028v-.048l-.002-.038-.002-.03-.002-.048-.003-.036v-.03l-.003-.048-.003-.038v-.03-.05l-.003-.036-.002-.03-.002-.047-.003-.038-.002-.03-.004-.05v-.066l-.003-.048-.003-.035c-.001-.007-.002-.02-.002-.032s-.003-.023-.003-.036l-.003-.035c-.001-.007-.002-.022-.002-.032s-.002-.025-.004-.036l-.003-.035v-.032l-.004-.035-.005-.036v-.032a.29.29 0 0 0-.004-.038l-.005-.035-.004-.034c-.002-.012-.003-.022-.003-.034l-.005-.038-.002-.032c0-.012-.003-.025-.003-.038l-.005-.036-.004-.034-.006-.035-.005-.036s-.002-.023-.005-.033a.41.41 0 0 1-.005-.038l-.005-.036-.004-.035s-.002-.023-.005-.035l-.005-.035-.004-.035-.006-.038-.005-.035-.006-.035-.006-.038-.005-.036-.006-.035c-.004-.014-.006-.024-.007-.036l-.005-.036-.006-.036a.34.34 0 0 1-.005-.036l-.006-.036-.007-.035-.014-.073c-.001-.012-.004-.022-.006-.036l-.007-.034c-.001-.012-.002-.013-.004-.02l-.01-.052-.006-.035-.014-.073a.58.58 0 0 1-.008-.033l-.004-.02-.012-.052-.007-.038c-.004-.03-.006-.03-.007-.035l-.007-.036s-.006-.022-.007-.033-.002-.014-.005-.02l-.012-.05v-.034c-.004-.012-.004-.013-.005-.02l-.013-.052-.01-.032s-.002-.014-.005-.02l-.013-.05-.01-.033-.006-.022c-.005-.014-.005-.026-.006-.028-.002-.012-.005-.014-.007-.02l-.012-.032c-.004-.01-.005-.015-.006-.022l-.015-.05-.01-.032s-.005-.015-.006-.022l-.015-.05-.012-.043s-.006-.013-.008-.02l-.014-.05c-.006-.012-.01-.022-.012-.032s-.006-.015-.008-.023c-.007-.025-.012-.036-.017-.048l-.013-.033c-.005-.01-.005-.016-.007-.022l-.016-.05a.55.55 0 0 1-.012-.032c-.002-.012-.006-.015-.01-.023l-.017-.05c-.006-.023-.01-.03-.013-.04s-.007-.015-.01-.025a.99.99 0 0 0-.019-.053l-.02-.055-.022-.054-.022-.055-.022-.054-.025-.054c-.01-.018-.014-.038-.023-.054s-.015-.038-.024-.055-.016-.036-.024-.054l-.026-.055-.025-.054-.027-.054a1.67 1.67 0 0 1-.027-.054l-.027-.055-.028-.053-.028-.055-.03-.054a1.43 1.43 0 0 0-.03-.055l-.03-.054-.03-.055c-.008-.017-.022-.036-.033-.054l-.033-.054-.034-.054-.034-.055-.036-.054-.037-.054-.036-.054-.04-.055-.04-.054-.084-.108c-.015-.016-.03-.036-.044-.054l-.045-.055-.046-.054-.047-.054-.05-.054-.05-.055-.053-.055-.054-.054-.058-.054-.06-.054-.06-.055-.064-.054a3.06 3.06 0 0 0-.863-.509l-1.72.206a2.41 2.41 0 0 0-.395.033c.228-.694.77-1.18 1.347-1.273.204-.56.74-1.05 1.313-1.184.453-.768 1.24-1.165 2.098-1.2 1.168-.05 2.118.46 3.028 1.065.98.68 1.73 1.646 2.293 2.863l.025.054.023.055.025.054a.83.83 0 0 0 .024.054 1.15 1.15 0 0 0 .024.054l.024.055.023.055.023.054.02.054.023.054c.01.018.013.036.022.055l.02.054.022.054.04.108c.007.016.012.036.018.055l.04.108a.67.67 0 0 0 .02.054l.018.055.036.108.017.054.018.055a1.91 1.91 0 0 1 .017.054l.018.055.017.054.016.055.016.053a1.07 1.07 0 0 0 .015.055l.017.054.015.054.016.054c.006.016.01.038.015.055l.014.054.015.055a.5.5 0 0 0 .014.054l.013.054a.51.51 0 0 0 .015.054l.014.055.014.054.012.055.013.053.005.025.007.03.01.048.01.036.007.032c.002.012.007.023.01.036.005.025.007.028.01.035a.69.69 0 0 0 .007.032c.003.012.008.022.008.035l.008.036.006.032c.002.012.008.025.01.036l.007.035a.69.69 0 0 0 .007.032l.008.047.006.036.007.033c.003.012.007.023.008.036l.007.035.007.033c.003.01.004.025.008.036l.007.036.006.033c.002.013.005.022.008.035l.006.036a.69.69 0 0 0 .007.032l.014.073.014.068.006.038.007.033.007.036.006.035.006.036.006.035.006.04.006.033.006.036.012.07a.32.32 0 0 0 .006.035l.006.036.006.034.018.1s.002.023.006.035l.01.072a.34.34 0 0 1 .005.036l.006.036c.002.012.002.022.004.035l.007.036.005.035.007.036.004.035.005.036c.002.012.002.025.005.038s.002.023.005.036l.003.035.006.035.004.035.004.02.01.086.004.02.006.05.005.034.002.02.007.053.004.032c.002.01.002.013.002.02l.006.05.004.034a.18.18 0 0 0 .002.02c.005.027.005.04.006.052l.004.032c.002.012.002.015.002.022l.005.05a.84.84 0 0 1 .004.032l.002.022a.45.45 0 0 0 .006.049l.004.032c.002.012.001.014.001.022l.006.05.002.032.002.022.004.05.002.042.002.023.004.05.003.042a.24.24 0 0 0 .002.025l.006.048.002.042a.24.24 0 0 0 .002.025l.003.05.003.04.002.026v.113l.005.048.002.04.002.026.003.048.003.04s.002.016.002.027l.005.048c0 .023.001.03.002.04l.002.027v.048.04l.001.027v.047l.003.04s.002.016.002.027a.35.35 0 0 1 .003.05l.003.04.002.028.003.048.005.067.003.048.002.04.002.028v.048.038l.002.028.002.048v.038l.002.03.001.05.002.036.002.03.002.047.003.038.001.03.001.05v.035.03a1 1 0 0 1 .001.048l.002.036.002.032.002.048a.26.26 0 0 0 .001.035v.03l.002.048.002.036v.03a1.04 1.04 0 0 1 .001.048.39.39 0 0 1 .002.036l.001.032v.05l.002.035v.032l.002.035v.036l.001.032.002.074.001.032a.46.46 0 0 1 .001.036v.036c.001.012.001.022.001.033l.001.036.001.038.001.032v.106l.001.036v.038l.001.033v.036l.001.035v.18l.001.034v.1l.001.035v.1l.001.038v.215a.72.72 0 0 1 .001.036v15.92l-2.56-1.373m5.586-9.134h2.36v-.308c-.638-.04-.697-.16-.697-.67v-4.24c0-.915.52-1.387 1.248-1.387.835 0 1.347.53 1.347 1.407v4.12c0 .512-.158.728-.757.77v.308h1.883v-.308c-.6-.04-.757-.257-.757-.77v-3.905c0-1.22-.536-1.933-1.903-1.933-1.375 0-2.025.742-2.025 1.972v3.965c0 .5-.058.63-.697.67v.308m5.26-6.74v.3c.472.02.63.198.63.493v3.076c0 .424-.118.493-.65.514v.3l1.435.058v-.944h.02c.266.552.652 1.004 1.325 1.004.818 0 1.2-.53 1.2-1.398v-2.62c0-.335.138-.473.6-.493v-.3H483.2v3.502c0 .65-.248.866-.584.866-.525 0-1.06-.7-1.06-1.655v-1.9c0-.295.158-.473.634-.493v-.3h-2.108m4.793 0v.3c.47.02.63.198.63.493v3.136c0 .424-.117.492-.63.513v.3l1.474.06v-4.018c0-.295.157-.473.63-.493v-.3zm1.474 6.225c0-.374-.206-.63-.5-.63s-.5.257-.5.63.205.63.5.63.5-.255.5-.63m2.16.287v-1.8h1.18v-.37h-1.18v-3.47c0-.434.15-.6.415-.6.326 0 .574.207.574 1.252v.276h.3v-.464c0-.996-.36-1.434-1.1-1.434-.65 0-1.042.408-1.042 1.197v3.254h-.6v.3c.708.295 1.08.63 1.14 1.888h.314"/><path d="M491.105 1150.62c0 1.266.375 1.762.938 1.762.517 0 .812-.496.812-1.762zm2.713-.37c0 1.418-.688 2.44-1.78 2.44-1.1 0-1.898-1.02-1.898-2.47 0-1.232.806-2.47 2.026-2.47 1.11 0 1.59.853 1.676 1.73l-.3.06c-.1-.67-.404-1.42-1.263-1.42-.66 0-1.164.75-1.164 2.13h2.713"/><path d="M495.273 1150.2c0 1.518.355 2.13.894 2.13.6 0 .963-.73.963-2.13 0-1.697-.52-2.13-1.04-2.13-.5 0-.816.612-.816 2.13zm1.22 4.13c.5-.02.638-.1.638-.5v-1.765l-.02-.01c-.197.383-.53.655-.992.655-1.032 0-1.8-1.06-1.8-2.5 0-1.548.817-2.45 1.7-2.45.6 0 .924.34 1.14.803h.02v-.684l1.376.058v.3c-.393-.01-.57.148-.57.68v5.77l-1.484-.06v-.308m2.5-6.43v.3c.6.04.688.157.688.67v4.802c0 .5-.1.63-.688.67v.308h2.378v-.308c-.6-.04-.727-.16-.727-.67v-2.044h2.12v2.044c0 .5-.117.63-.725.67v.308h2.377v-.308c-.6-.04-.688-.16-.688-.67v-4.802c0-.514.098-.632.688-.67v-.3h-2.377v.3c.608.04.725.157.725.67v2.388h-2.12v-2.388c0-.514.118-.632.727-.67v-.3H499m6.43 2.73c0 1.266.375 1.762.938 1.762.517 0 .812-.496.812-1.762zm2.713-.37c0 1.418-.688 2.44-1.78 2.44-1.1 0-1.898-1.02-1.898-2.47 0-1.232.807-2.47 2.026-2.47 1.1 0 1.6.853 1.676 1.73l-.3.06c-.1-.67-.405-1.42-1.263-1.42-.662 0-1.164.75-1.164 2.13h2.713m2.827-.423c0-1.115-.455-1.706-.958-1.706-.306 0-.542.257-.542.78 0 .837.7 1.212 1.5 1.5zm1.332-.6c-.02-.7-.097-.928-.283-.928-.137 0-.205.128-.205.413v2.742c0 .74-.423 1.237-1.525 1.237-.857 0-1.486-.527-1.486-1.197 0-.395.197-.592.472-.592s.492.217.492.572c0 .287-.1.523-.413.553.206.245.5.355.837.355.522 0 .78-.247.78-.8v-.8c-.85-.315-2.405-.78-2.405-1.904 0-.65.442-1.1 1.2-1.1.7 0 .986.32 1.225.764h.02c.06-.53.324-.764.796-.764.604 0 .807.438.807 1.474h-.3m.4-1.38v.3c.472.02.63.198.63.492v5.118c0 .335-.167.512-.65.533v.3l1.495.058v-6.018c0-.294.157-.472.63-.492v-.3h-2.104m3.693 6.52v-1.8h1.182v-.37h-1.182v-3.47c0-.434.15-.6.415-.6.326 0 .573.207.573 1.252v.276h.3v-.464c0-.996-.36-1.434-1.1-1.434-.65 0-1.042.408-1.042 1.197v3.254h-.6v.3c.708.295 1.08.63 1.14 1.888h.315m1.556-6.54v.3c.472.02.63.198.63.493v5.138c0 .422-.118.5-.65.5v.308l1.494.06v-2.885h.02c.198.433.574.885 1.237.885.76 0 1.23-.53 1.23-1.398v-2.62c0-.295.167-.473.6-.493v-.3h-1.454v3.45c0 .7-.247.917-.603.917-.495 0-1.04-.65-1.04-1.596v-1.97c0-.295.16-.473.633-.493v-.3h-2.108m10.696 6.764v-2.6h-.3c-.256 1.65-.67 2.396-1.597 2.396-.777 0-1.498-.648-1.498-3.162 0-2.42.7-3.17 1.498-3.17.67 0 1.026.434 1.026 1.6 0 1.026-.148 1.183-.927 1.222v.3h2.618v-.3c-.6-.04-.727-.157-.727-.67v-2.365h-.315c-.118.217-.216.375-.315.375-.128 0-.14-.128-.523-.325-.256-.137-.58-.205-.887-.205-1.282 0-2.553 1.237-2.553 3.54 0 1.983 1.184 3.53 2.583 3.53.354 0 .7-.107 1.004-.28.2-.117.277-.205.365-.205.1 0 .168.118.247.332h.3m1.04-6.774v.3c.413.02.57.198.57.493v2.68c0 .672-.118.888-.6.908v.3l1.356.058v-1.137h.02c.127.512.482 1.197 1.075 1.197.363 0 .717-.3.717-.852 0-.425-.207-.64-.46-.64-.217 0-.443.138-.443.58 0 .237.137.484.423.484-.05.077-.147.118-.257.118-.67-.01-.976-1.45-.976-2.308v-1.4c0-.295.158-.473.828-.493v-.3h-2.244m4.23 2.362c0 1.707.393 2.16.946 2.16s.947-.454.947-2.16-.396-2.16-.947-2.16-.946.454-.946 2.16zm-.905 0c0-1.5.924-2.47 1.85-2.47s1.85.98 1.85 2.47-.924 2.47-1.85 2.47-1.85-.98-1.85-2.47m8.32-2.3l-1.327-.058v.884h-.02c-.245-.58-.6-1.004-1.287-1.004-.825 0-1.23.423-1.23 1.398v2.6c0 .424-.118.493-.55.514v.3l1.396.058v-3.66c0-.6.236-.77.56-.77.56 0 1.023.78 1.023 1.596v1.95c0 .424-.118.493-.62.514v.3l1.465.058v-3.898c0-.384.166-.473.6-.493v-.3m1.517 2.094c0 1.677.5 2.288 1 2.288s.855-.612.855-2.13c0-1.5-.353-2.13-.873-2.13-.403 0-.983.454-.983 1.973zm.727-3.948v.3c-.57.02-.727.197-.727.5v1.5h.02c.196-.364.52-.635 1.03-.635 1.07 0 1.77 1.1 1.77 2.47 0 1.007-.56 2.47-1.68 2.47-.628 0-1.03-.448-1.18-.92h-.02v.92l-1.415-.06v-.3c.5-.02.63-.1.63-.513v-4.922c0-.295-.157-.472-.63-.5v-.3h2.202"/></g></g></svg>');```
Grafana dashboard
To import the dashboard, find the Import menu. The location might differ depending on your installed Grafana version, but that menu should always be somewhere.
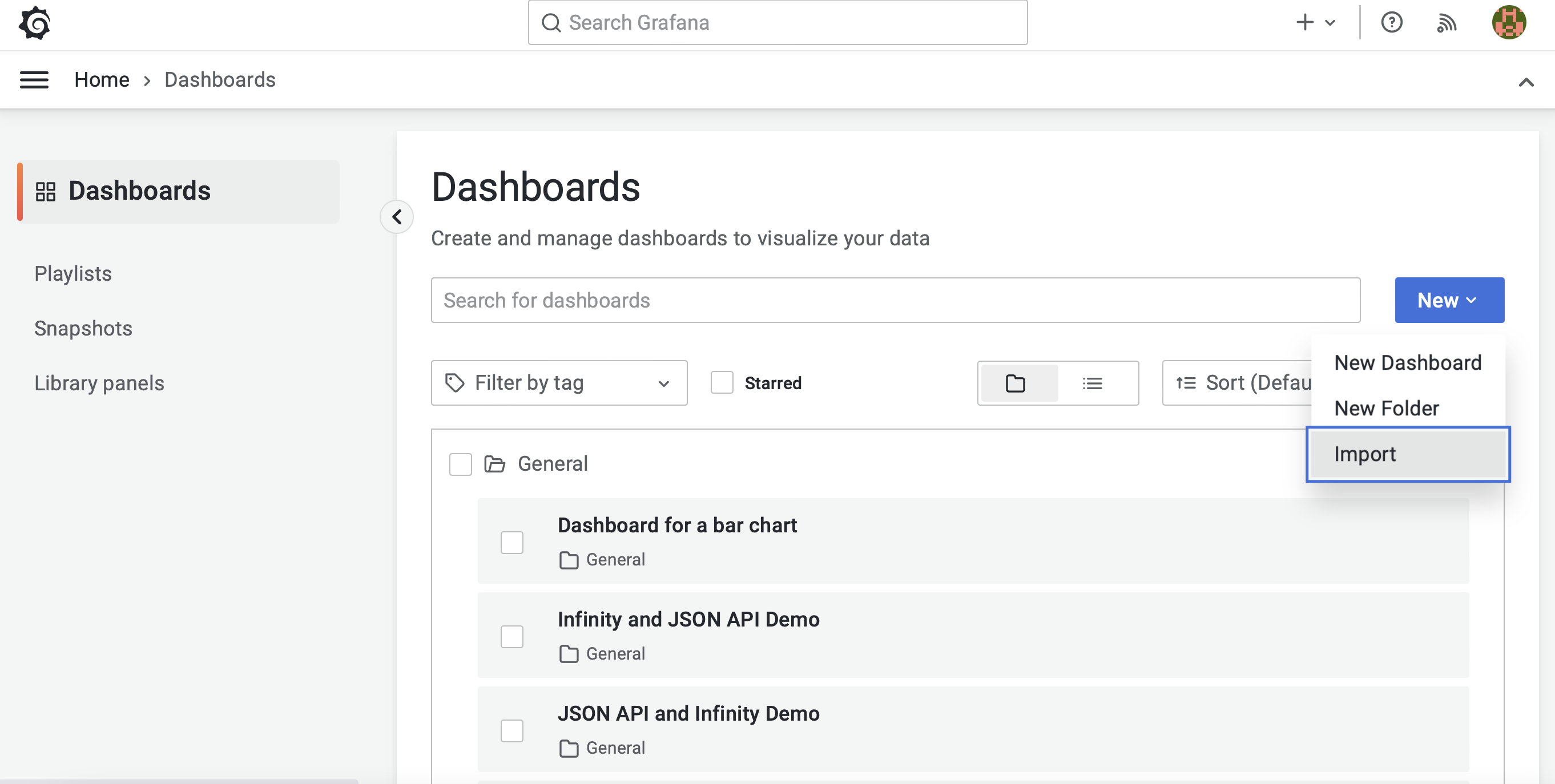
For the code to function correctly, you will need to have the PostgreSQL data source setup and have the same tables and materialized view in your database.
Grafana dashboard source code from the video
{
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": {
"type": "grafana",
"uid": "-- Grafana --"
},
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
"target": {
"limit": 100,
"matchAny": false,
"tags": [],
"type": "dashboard"
},
"type": "dashboard"
}
]
},
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
"id": 8,
"links": [],
"liveNow": false,
"panels": [
{
"datasource": {
"type": "postgres",
"uid": "LE7tFO2Vk"
},
"gridPos": {
"h": 11,
"w": 24,
"x": 0,
"y": 0
},
"id": 4,
"options": {
"baidu": {
"callback": "bmapReady",
"key": ""
},
"editor": {
"format": "auto",
"height": 1802
},
"getOption": "const series = data.series.map((s) => {\n if (s.refId == 'data') {\n const datetime = s.fields.find((f) => f.name === 'datetime').values.buffer;\n const open = s.fields.find((f) => f.name === 'open').values.buffer;\n const high = s.fields.find((f) => f.name === 'high').values.buffer;\n const low = s.fields.find((f) => f.name === 'low').values.buffer;\n const close = s.fields.find((f) => f.name === 'close').values.buffer;\n const volume = s.fields.find((f) => f.name === 'volume').values.buffer;\n\n return datetime.map((d, i) => [d, open[i], close[i], low[i], high[i], volume[i]]);\n }\n\n if (s.refId === 'images') {\n image = s.fields.find((f) => f.name === 'image_svgxml').values.buffer;\n stock_symbol = s.fields.find((f) => f.name === 'stock_symbol').values.buffer;\n stock_name = s.fields.find((f) => f.name === 'stock_name').values.buffer;\n scaleX = s.fields.find((f) => f.name === 'scalex').values.buffer;\n scaleY = s.fields.find((f) => f.name === 'scaley').values.buffer;\n }\n\n})[0];\n\nconsole.log(series.map((arr) => arr[0]));\n\nreturn {\n legend: {\n show: false,\n },\n tooltip: {\n triggerOn: 'none',\n transitionDuration: 0,\n confine: true,\n borderRadius: 4,\n borderWidth: 1,\n borderColor: '#333',\n backgroundColor: 'rgba(255,255,255,0.9)',\n textStyle: {\n fontSize: 12,\n color: '#333'\n },\n position: function (pos, params, el, elRect, size) {\n const obj = {\n top: 60\n };\n obj[['left', 'right'][+(pos[0] < size.viewSize[0] / 2)]] = 5;\n return obj;\n }\n },\n animation: true,\n // color: colorList,\n tooltip: {\n triggerOn: 'none',\n transitionDuration: 0,\n confine: true,\n borderRadius: 4,\n borderWidth: 1,\n borderColor: '#333',\n backgroundColor: 'rgba(255,250,250,0.9)',\n textStyle: {\n fontSize: 18,\n color: '#333'\n },\n\n },\n axisPointer: {\n link: [\n {\n xAxisIndex: [0, 1]\n }\n ]\n },\n dataZoom: [\n {\n type: 'slider',\n xAxisIndex: [0, 1],\n realtime: false,\n top: 65,\n height: 20,\n handleSize: '170%'\n },\n ],\n xAxis: [\n {\n type: 'time',\n boundaryGap: true,\n min: 'dataMin',\n max: 'dataMax',\n axisPointer: {\n show: true\n }\n },\n {\n type: 'time',\n gridIndex: 1,\n boundaryGap: false,\n splitLine: { show: false },\n axisLabel: { show: false },\n axisTick: { show: false },\n axisLine: { lineStyle: { color: '#777' } },\n min: 'dataMin',\n max: 'dataMax',\n axisPointer: {\n type: 'shadow',\n label: { show: false },\n triggerTooltip: true,\n handle: {\n show: true,\n margin: 30,\n color: '#0000a0'\n }\n }\n }\n ],\n yAxis: [\n {\n scale: true,\n splitNumber: 2,\n axisLine: { lineStyle: { color: '#777' } },\n splitLine: { show: true },\n axisTick: { show: false },\n axisLabel: {\n inside: true,\n formatter: '{value}\\n'\n }\n },\n {\n scale: true,\n gridIndex: 1,\n splitNumber: 2,\n axisLabel: { show: false },\n axisLine: { show: false },\n axisTick: { show: false },\n splitLine: { show: false }\n }\n ],\n grid: [\n {\n left: 20,\n right: 20,\n top: 110,\n height: 120\n },\n {\n left: 20,\n right: 20,\n height: 40,\n top: 260\n }\n ],\n graphic: [//stock_symbol\n {\n type: 'image',\n y: 10,\n scaleX: scaleX[0],\n scaleY: scaleY[0],\n right: 130,\n z: 0,\n style: {\n image: 'data:image/svg+xml;utf8,' + image[0],\n }\n }\n ],\n series: [\n {\n name: 'Volume',\n type: 'bar',\n xAxisIndex: 1,\n yAxisIndex: 1,\n itemStyle: {\n color: '#0000a0',\n },\n emphasis: {\n itemStyle: {\n }\n },\n data: series.map((arr) => [arr[0], arr[5]]),\n },\n {\n type: 'candlestick',\n data: series.map((arr) => [arr[0], arr[1], arr[2], arr[3], arr[4]]),\n itemStyle: {\n color: '#ff5656',\n color0: '#0000a0',\n borderColor: '#ff5656',\n borderColor0: '#0000a0'\n },\n emphasis: {\n itemStyle: {\n color: 'black',\n color0: '#444',\n borderColor: 'black',\n borderColor0: '#444'\n }\n }\n },\n ]\n};",
"map": "json",
"renderer": "canvas"
},
"targets": [
{
"datasource": {
"type": "postgres",
"uid": "LE7tFO2Vk"
},
"editorMode": "code",
"format": "table",
"hide": false,
"rawQuery": true,
"rawSql": "SELECT $var_dt as datetime, open, high, low, close, volume, stock_symbol\nFROM $var_granularity where stock_symbol = '$var_stock_symbol'\n and $var_dt::date <= '2023-01-07';",
"refId": "data",
"sql": {
"columns": [
{
"parameters": [],
"type": "function"
}
],
"groupBy": [
{
"property": {
"type": "string"
},
"type": "groupBy"
}
],
"limit": 50
}
},
{
"datasource": {
"type": "postgres",
"uid": "LE7tFO2Vk"
},
"editorMode": "code",
"format": "table",
"hide": false,
"rawQuery": true,
"rawSql": "SELECT image_svgxml, scaleX as scalex, scaleY as scaley, stock_symbol, stock_name FROM stock_image \nwhere stock_symbol = '$var_stock_symbol';",
"refId": "images",
"sql": {
"columns": [
{
"parameters": [
{
"name": "image_svgxml",
"type": "functionParameter"
}
],
"type": "function"
},
{
"parameters": [
{
"name": "stock_symbol",
"type": "functionParameter"
}
],
"type": "function"
},
{
"parameters": [
{
"name": "stock_name",
"type": "functionParameter"
}
],
"type": "function"
}
],
"groupBy": [
{
"property": {
"type": "string"
},
"type": "groupBy"
}
],
"limit": 50
},
"table": "stock_image"
}
],
"title": "$var_stock_symbol",
"type": "volkovlabs-echarts-panel"
}
],
"refresh": false,
"schemaVersion": 37,
"style": "dark",
"tags": [],
"templating": {
"list": [
{
"current": {
"selected": false,
"text": "AMZN",
"value": "AMZN"
},
"datasource": {
"type": "postgres",
"uid": "LE7tFO2Vk"
},
"definition": "SELECT distinct stock_symbol from stock_image;",
"hide": 0,
"includeAll": false,
"label": "Symbol",
"multi": false,
"name": "var_stock_symbol",
"options": [],
"query": "SELECT distinct stock_symbol from stock_image;",
"refresh": 1,
"regex": "",
"skipUrlSync": false,
"sort": 0,
"type": "query"
},
{
"current": {
"selected": false,
"text": "stocks:stocks",
"value": "stocks:stocks"
},
"hide": 0,
"includeAll": false,
"label": "Granularity",
"multi": false,
"name": "var_granularity",
"options": [
{
"selected": true,
"text": "5min",
"value": "stocks"
},
{
"selected": false,
"text": "1hour",
"value": "one_hour_candle"
}
],
"query": "5min : stocks, 1hour : one_hour_candle",
"queryValue": "",
"skipUrlSync": false,
"type": "custom"
},
{
"current": {
"selected": false,
"text": "bucket",
"value": "bucket"
},
"datasource": {
"type": "postgres",
"uid": "LE7tFO2Vk"
},
"definition": "select case when '$var_granularity' = 'stocks' then 'datetime' else 'bucket' end;",
"hide": 0,
"includeAll": false,
"multi": false,
"name": "var_dt",
"options": [],
"query": "select case when '$var_granularity' = 'stocks' then 'datetime' else 'bucket' end;",
"refresh": 1,
"regex": "",
"skipUrlSync": false,
"sort": 0,
"type": "query"
}
]
},
"time": {
"from": "now-6h",
"to": "now"
},
"timepicker": {},
"timezone": "",
"title": "Twelve",
"uid": "a5rFsShVz",
"version": 64,
"weekStart": ""
}
Feel free to ask questions and let me know if I forgot any steps. I will gladly alter the instructions accordingly.
Summary
PostgreSQL combines the three most required storage needs:
- Configuration,
- Time-series,
- Relational.
Those are the three primary storage needs for our commercial applications. PostgreSQL was an easy and obvious choice.
Let’s Stay Connected!
Join the Conversation: Stay updated and share your thoughts! Subscribe to our YouTube Channel and leave your comments—we can’t wait to hear what you think.
Your input helps us improve, so don’t hesitate to get in touch!


