Display large PDF documents in Grafana


In the recent article on our blog, we delved into the advantages of utilizing Docker containers and initial provisioning when crafting our panel plugin template for Grafana. This approach has proven to be valuable when implementing the current feature request for Business Media panel and letting us swiftly provide solutions for long-term plugin support.
During the creation of Business Media panel for one of our projects, we also included support for displaying PDF documents. It's satisfying to see that the plugin is now used to display PDF files stored in databases such as PostgreSQL.
For an in-depth overview of the plugin, feel free to check out the video on our YouTube channel.
PDF documents
PDF documents are classified into four categories based on their size:
- small (10-100kb)
- medium (100-1MB)
- large (1-16MB)
- huge (16-128MB)
Our plugin was designed to support small and medium-sized PDF documents that you can easily test without setting up a separate database for storage. For this purpose, we have used the Business Input data source and stored the data in the dashboard.
To validate and assess the plugin's performance when showcasing large PDF documents, we followed these steps:
- Installed PostgreSQL.
- Loaded PDF documents into the database.
- Created a data source and dashboard to facilitate validation and performance checks.
Furthermore, it is essential to verify that the script is easily deployable for continuous integration and development purposes.
PostgreSQL
From Grafana's perspective, all data sources are the same because they return data frames. We received a feature request for the plugin to enable display of large PDF documents retrieved from a PostgreSQL database.
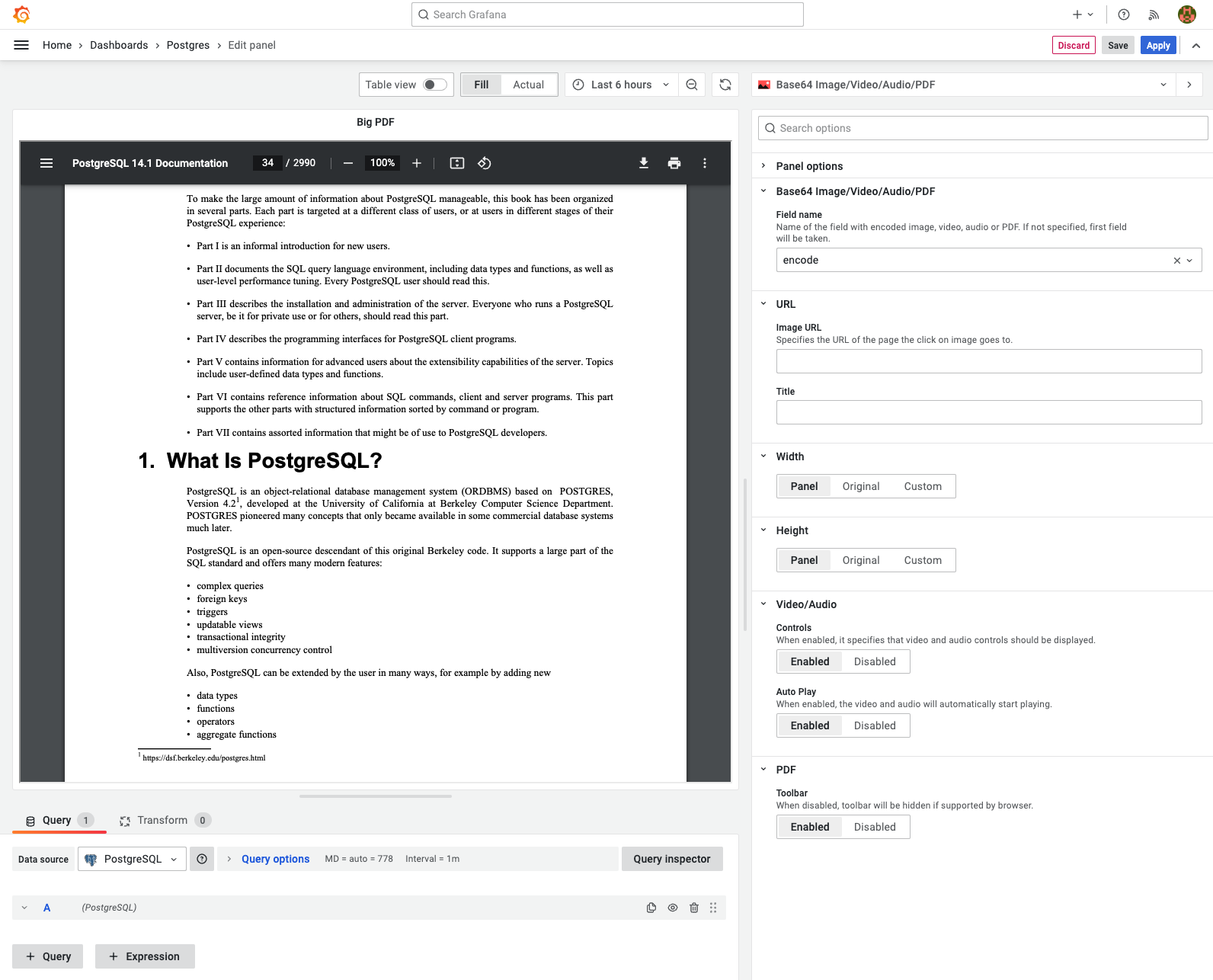
To install PostgreSQL, we added a container with the latest version of the postgres image. We specified a volume for the folder /docker-entrypoint-initdb.d, which takes care of creating necessary tables and permissions when starting.
postgres:
image: postgres
restart: always
environment:
POSTGRES_PASSWORD: postgres
ports:
- 5432:5432
volumes:
- ./postgres:/docker-entrypoint-initdb.d
In our case, it was a table with the bytea fields to store binary data with unique names. When images and PDF documents are retrieved from the database, they can be stored in the Base64 format or transformed using the encode() command.
CREATE TABLE images (name text, img bytea, UNIQUE(name));
Loading PDF files into the database
To load PDF documents and test images into the database, we created a Node.js script.
loading...
Provisioning
The initial provisioning configuration that adds a new dashboard for PostgreSQL is already present in our plugin template.
apiVersion: 1
providers:
- name: Default # A uniquely identifiable name for the provider
type: file
options:
path: /etc/grafana/provisioning/dashboards
We have included a configuration to provision a PostgreSQL data source with SSL disabled, as well as a specific login, password, and URL pertaining to the database setup.
apiVersion: 1
datasources:
- name: PostgreSQL
type: postgres
access: proxy
orgId: 1
version: 1
editable: true
url: postgres:5432
user: postgres
uid: P1D2C73DC01F2359A
jsonData:
postgresVersion: 1200
sslmode: disable
secureJsonData:
password: postgres
You can find more information about the PostgreSQL data source in the official documentation.
Load data
The final step is to start containers and load data. When they start, Grafana and PostgreSQL will be automatically provisioned and ready for use.
It takes around 1-2 seconds to load a 13-megabyte PDF document with 2,990 pages. The user who requested this feature was pretty happy with results, therefore we passed the plugin to the Grafana team for review and approval, and it was later added to the Grafana Plugins catalog.
We're Always Happy to Hear From You!
We value your feedback and are eager to connect with our community and partners. Whether you have a question, an idea, or an issue to report, here’s how you can reach out:
- Community Members: Have a question, want to suggest a new feature, or found a bug? We’d love to hear from you! Please create a GitHub issue to start the conversation.
- Enterprise Partners: Need assistance or have an urgent request? Open a Zendesk ticket for a prompt and dedicated response from our team.
- Join the Conversation: Stay updated and share your thoughts! Subscribe to our YouTube Channel and leave your comments—we can’t wait to hear what you think.
Your input helps us improve, so don’t hesitate to get in touch!


